Jekyll2026-04-07T20:15:54+00:00https://mattandrews.info/feed/talks.xmlMatt Andrews | TalksMatt Andrews is an engineering manager based in Birmingham, UK. He also enjoys riding bikes, brewing craft beer, writing and making things.
Making Desktop Apps With Electron2017-03-13T23:00:00+00:002017-03-13T23:00:00+00:00https://mattandrews.info/talks/2017/03/13/making-desktop-apps-with-electronMy team were exploring auto-generating animations from audio files. We were wondering if it was possible, given a voice recording, to automatically output a video of some lips "speaking" the words.
With a bit of searching I came across Rhubarb, a great library for generating "mouth shapes" (eg. letters corresponding to commonly-understood lip positions in animation). I wrote a Node app to take an audio file, generate mouth shapes, then feed these shapes into ffmpeg using some pre-created lip images, in order to output a video.
The results looked like this:
Donald Trump "speaking"
This was all fine, but it was less than usable for the non-technical members of my team. Here's what they would have had to do to generate this output:
If you're not a developer and not comfortable using the terminal, this isn't much fun. Passing arguments and parameters can be confusing at the best of times. Clearly something else was needed.
Enter Electron
I'd already heard of Electron – I'd been using Atom for a year or two, which I knew was built on top of it. If you're not familiar, it's effectively a bundled up browser (Chrome, via Chromium) which has access to the wider filesystem than a regular browser. Electron lets you write an app for multiple desktop platforms in HTML, CSS and JavaScript.
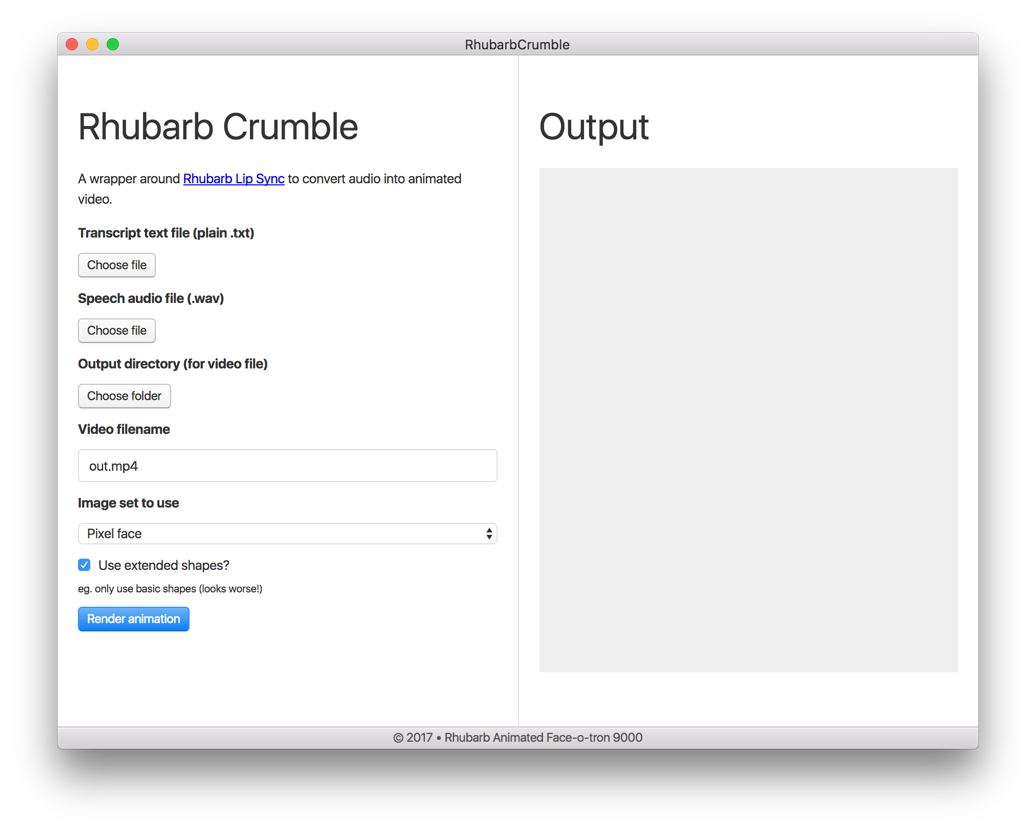
I was able to quickly put together this simple app in less than half a day's work:
Version 0.1 of my Electron app
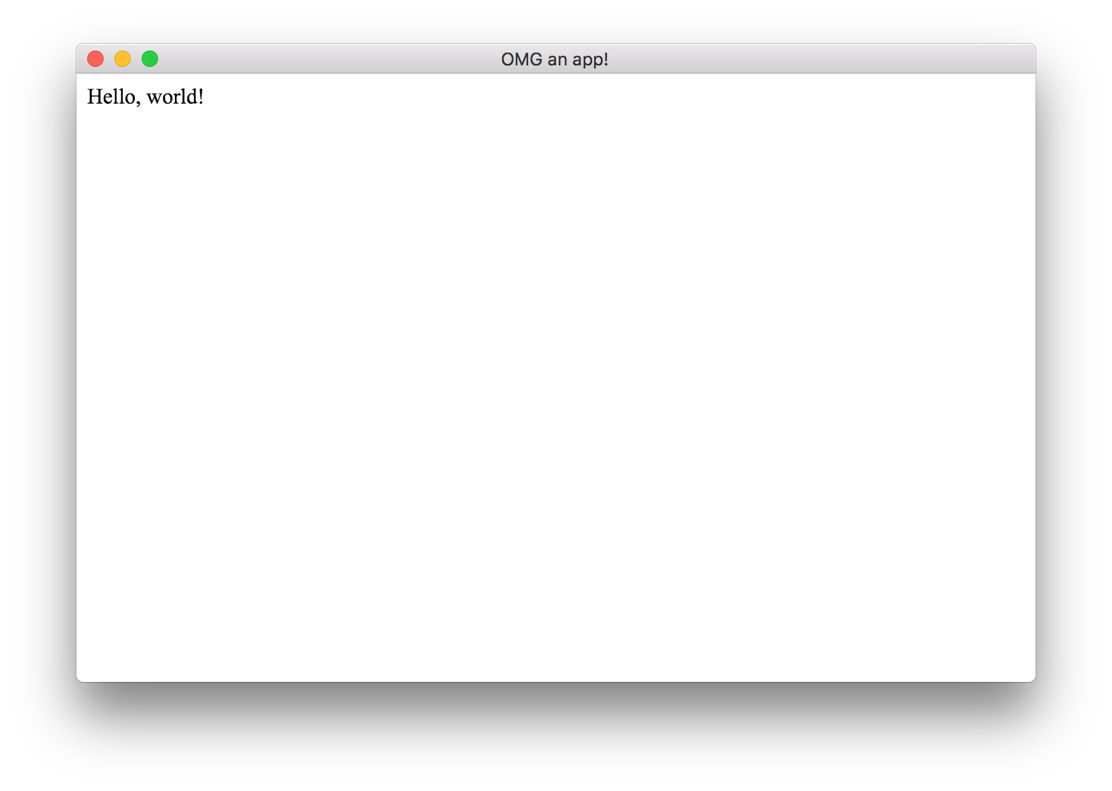
In order to get off the ground with Electron, some code similar to this will give you a super-basic "Hello, world!":
Note: I've stripped a few things for brevity here, eg. window management. See the Echo docs for more code samples.
This is enough to get you up and running – it'll load up a file called index.html that's in the same directory as that code (inside main.js). When you add a "main": "main.js" entry to your package.json file, you can run electron . and you'll get a running app you can demo:
The most basic app you can start with Electron
Distribution
After you get over the initial excitement of making a real, proper desktop app (it shows up in the dock! It's got an icon! You can minimise it!), you might be wondering how to make a distributable version of it, so everyone can see your "Hello, world!" glory.
If you install electron-packager you can run the command below and output four apps for all the platforms Electron supports: Windows, Linux, OS X and Mac App Store.
$ npm install-g electron-packager
$ electron-packager .--icon icon.icns --platform all
Processes in Electron
Electron has two main processes where your code runs:
Main process
This is the part shown above – it's effectively the "server-side" of your app. Here you can manipulate the filesystem, load dependencies, manage configuration and do any background tasks your app needs. In mine, I go and fetch the ffmpeg binaries (eg. specific to the user's platform) at runtime.
Renderer process
The Renderer can be thought of as the "client-side" of your app. Here's the browser window where your HTML, CSS and JavaScript is executed. There are a few conventions that are different from a browser – for exampler, my app needed a file picker input. I started off using the standard HTML one but discovered that this didn't work as expected after packaging. Luckily Atom has a (more powerful) internal one you can use.
Communicating between processes
Once I'd got my app to show a UI onscreen for picking files and added some basic form validation, I needed to make a <button> element in the renderer process which would kick off my video task in the main process. To do this, you can use the ipc-renderer module for standard event emitting.
Main process
const{ipcMain}=require('electron');// publishwindow.webContents.send('event-from-main',{data:'bar'});// subscribeipcMain.on('event-from-renderer',(event,arg1)=>{console.log('Message from renderer',arg1);});
Renderer process
const{ipcRenderer}=require('electron');// subscribeipcRenderer.on('event-from-main',(event,arg1)=>{console.log('Message from main',arg1);});// publishipcRenderer.send('event-from-renderer',{data:'foo'});
This code (above) will use standard pub/sub methods so you can communicate asynchronously between your process and bind events.
Why make a desktop app?
Okay, awesome – you can package up HTML into a desktop app. But why do you want to do this? Perhaps you might not have to!
Reasons to not make a desktop app
You’re bundling your existing website into an app
You’re bundling your existing website into an app
You’re bundling your existing website into an app
You’re bundling your existing website into an app
You’re bundling your existing website into an app
You’re bundling your existing website into an app
Come on. If you just package up an existing website into a desktop app, all you've done is invented a worse version of the web browser. Nobody needs this product and it'll just look lazy and pointless.
Reasons to make a desktop app
Assuming you're not bundling a website into an app, here are some good reasons for making a desktop app with Electron:
You need access to the filesystem (eg. browser limitations)
You’re making a GUI for a command-line app
You don’t want to learn existing desktop UI techniques
You probably already know most of the techniques (HTML/CSS/JS)
You’re building for an offline/deployed environment
Conclusions
So, Electron is pretty cool for the right tool. In my case, it meant I could take a command-line app and package it into a nice-looking, easily distributable desktop app which can be used by non-tech users without having to explain to them how (and why) to install brew, node and ffmpeg (and that's before we get to using my app itself).
There are some concerns – apps built with Electron have a large-ish footprint (my app for OS X is 294mb for a couple of hundred lines of code. Arguably this matters less as performance (in terms of file weight) is less of a worry for a packaged app, but it's still more bloated than traditional desktop app output. That said, in order to build one of those, you'd have to learn some brand new things from scratch, and they're unlikely to look as native as Electron apps do, on each platform. Atom also gets criticised for being slower than competitors. For me, these weren't issues – this app was definitely more user-friendly than my CLI version, even if it sacrificed some speed to get there.
If you want to know more, check out the official Electron docs and see what you can build.
Many thanks to Kath Preston (from 383) for organising Hydrahack where I gave this lightning talk.
]]>Why You Should Quit Your Job2016-05-31T23:00:00+00:002016-05-31T23:00:00+00:00https://mattandrews.info/talks/2016/05/31/why-you-should-quit-your-job
The Guardian's London offices in Kings Place
From 2010-2015 I worked here (above) at the Guardian newspaper as a client-side web developer. I started working there at the age of 23 and it was my dream job. I want to talk about realising when you're unhappy at work and what to do about it when it happens to you.
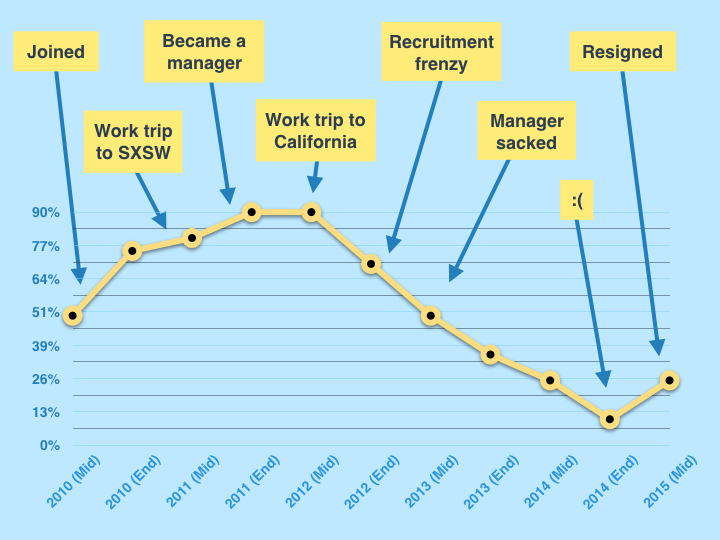
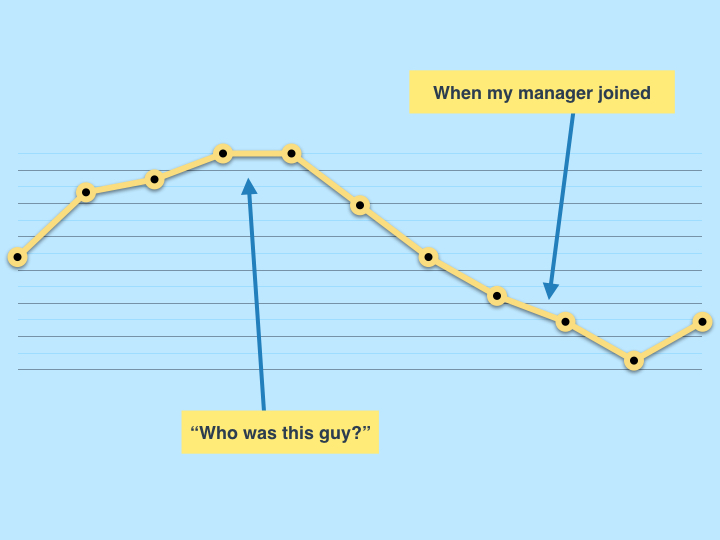
Over that time my career satisfaction had peaks and troughs. I recently attempted to chart my happiness at work:
A rough attempt at charting my job satisfaction over five years, coupled with major events at work
It took me a long time—too long—to realise I was unhappy, though. In retrospect, a year after leaving, I can see the signs and the factors which made it difficult for me to admit to myself that I was unhappy.
The fork in the road
In mid 2011 I was offered a the chance to take on management role where I'd divide my time between coding and management. At the time, the software developer role had no formal progression, which meant I was unclear about my next move. I was barely more than a junior developer but the opportunity to learn new things, get paid a bit more and take on more responsibility was exciting.
At first it was great. I was out of my depth but learned as I went. My new position meant I got to go on work trips abroad and be more involved with the running of the department, which was fun.
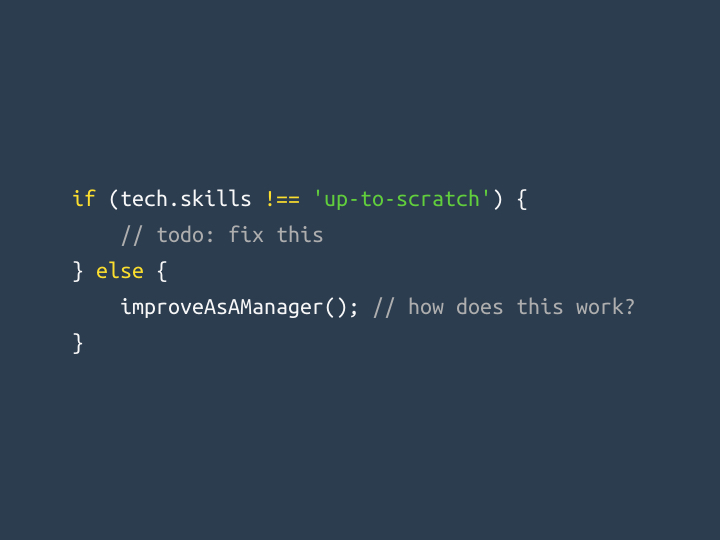
A nerdy hint of the challenge I faced
A year or so into the role, the department grew. I found myself spending a lot more than the promised 15% of my time reading CVs, conducting interviews and trying to run appraisals and one-to-ones. I felt my coding skills begin to suffer and was unable to find the time to improve them.
I started to get defensive, or perhaps over-sensitive, when others sensed my technical work wasn't up to scratch. I didn't really know what I could do to find the extra time to improve, and by taking the manager role I felt people assumed I had more advanced technical ability than I actually possessed.
The archetypal bad manager?
Similarly, I began to feel like I wasn't doing a great job as a manager either, with little guidance and motivation from above. We got some training but it never quite felt like I knew what I was doing, and the standard of management from others doing the same role as me seemed hugely varied and inconsistent.
A few years of this left me feeling like nobody was helping me develop and that I was left alone. I began to get cynical and started to run away from problems, moving teams to avoid working with challenging developers who brought my shortcomings into focus. I didn't realise then that I was unhappy, though. In retrospect, there were clear signs.
Signs I was unhappy
Getting into pointless debates
Spiderman vs Wolverine? Who gives a shit.
I found myself getting into heated debates about things I didn't really care about, if I was honest. Technical issues that I didn't really understand, product directions, anything. I'd take our my frustrations about my situation by arguing about things, not realising this was sidestepping my real issue. I wasn't brave enough to admit when I didn't understand things so used conversation as a mask.
Ignoring offers of help
Throwing away solutions
Colleagues who knew me well could spot that I wasn't at my best and would take me for chats, suggesting ideas and solutions for improving things. My pride meant I ignored these fixes, finding "reasons" to explain to myself why they wouldn't work. My problems were above my head and outside of my control, I'd reason. Or I'd tell myself that I shouldn't have to go out and figure out my own path, that someone should be figuring it out for me. Either way, finding reasons to avoid actively changing things was the easiest path.
Ranting on social media
Don't be the angry social media user
I sometimes even ranted on social media about work and my colleagues which eventually landed me in hot water. I was bitter and annoyed and couldn't understand why people weren't helping me. It seems obvious now but at the time I felt alone and misunderstood. In reality, being that person whining on Twitter is never a surefire route to finding help and support.
Things to do when unhappy at work
I'd left it too late. I refused to acknowledge that I wasn't enjoying my job, instead blaming circumstances and other people for things I wasn't bold enough to address. By the time I did realise it was down to me, it was too late for me to do things things that could've helped.
Talk to people
Coffee: solves all of life's problems
A few good colleagues could see I was frustrated and took me for a coffee. Plenty of others would've offered me useful advice if I'd bothered to ask them for it. I never did.
I was hardly the first person to struggle with the transition to manager, not even in my own department. Plenty of people I looked up to and respected would've had useful and inspirational words for me if I'd pursued them. My sense of entitlement (due to longevity) meant I was too proud to chase these solutions.
Work out what you can control
They don't make them like this anymore, but you get the idea
Most of my problems were things I could directly control, or at least influence. At the time I found it easier to blame outside factors for my issues.
Surrendering my control of the situation made it easier to pretend there was nothing I could do and allowed me to get more bitter and unhappy.
If I'd made a list of the problems I felt I had and categorised them by three headings: Control, Influence and No Control (or similar), I might've been quite surprised at which things I could've changed. By the end of my time in this job I was quite free to do and say what I wanted: I could have made use of this.
See it from their side
Remember my happiness graph? This is how my boss might've seen it
By the end, I felt like my boss wasn't interested in my development and blamed him for my lack of progress.
But he joined when I was at my lowest ebb – he'd never seen my at my best. What reason was I giving him to invest in me?
All he'd seen of me was someone past their best, negative and self-entitled. I didn't bother to stop and reflect on his motivation and understanding, I just allowed myself to feel mistreated. We are always in control of how we choose to react to something.
Ask for help
Bosses: not actually godlike beings
I ascribed opinions and behaviours to my manager based on my own assumptions. I never sat down and told him my problems directly. I assumed he knew what I wanted, and chose not to help me, which was easier than actually addressing my concerns.
Managers aren't all-knowing, omniscient beings. If I'd been straight with him about how I felt instead of taking offence I might've got more support.
Quit
But if you realise too late and your happiness quotient is in danger of reaching rock bottom, then it's time to leave. I resigned in spring 2015 and immediately felt better and found myself enjoying work again.
In retrospect now I can see that I ignored my problems and avoided addressing them until it was too late and the best option was for me to begin again.
Yep, I Instagrammed my resignation letter. Deal with it.
Sometimes it's about knowing when to move on. I found a new job that's stretched and challenged me. It was a leap in the dark to a team, city and role I'd had little experience of, but it was the right thing: I needed to be reminded that I could be excited, afraid and developer again.
Closing thoughts
Your mental wellbeing and health is too important to risk spending time in a job you're unhappy with. We work to live, not the other way around. I found myself unwilling to face up to the completely normal feeling of being unsatisfied with work, until it became too late to do anything about it. If you feel like this, maybe some of the tips above might help you rediscover your passion for your work. And if they aren't right for you, then maybe it's time you quit your job, too.
Many thanks to Mark Steadman for organising Ignite Brum where I gave this talk, and for motivating me to write it.
]]>The Blossoming of the Web2015-11-23T23:00:00+00:002015-11-23T23:00:00+00:00https://mattandrews.info/talks/2015/11/23/the-blossoming-of-the-webThis talk is a mixed bag of new(ish) developments in technology which intersect with journalism. I'm going to talk through six examples of things that I think are interesting that you should care about if you're a hack, a hacker, or that semi-mythical unicorn who claims to be both.
Hacks
I've divided the talk into two halves: Hacks, and Hackers. Let's start with three things that the Hacks might be interested in.
1. Google AMP
First up is a new project by Google: Accelerated Mobile Pages (AMP). It's gained some attention recently and, in my opinion, is of real interest to anyone connected with online publishing.
Google's basic premise with AMP is that the web is too slow. Specifically, they lay the blame for this at the feet of JavaScript:
"Once arbitrary JavaScript is in play, most bets are off because anything could happen at any time and it is hard to make any type of performance guarantee." (Malte Ubl, AMP project Tech Lead)
I suspect that the "arbitrary JavaScript" they refer to here is mostly confined to advertising/tracking code, which tends to proliferate on publishers' sites and often uses things like scrolljacking and animated/video elements which can slow down page rendering. This obviously has some major implications for news publishers wanting to AMP-ify their sites.
Here's a demo of AMP recorded live from my mobile phone. It's worth noting that this was done over wifi (because, ironically, I couldn't get a good enough 3G signal to show a typical loading scenario), but it still illustrates the concept and the new UI Google has produced for AMP-powered content.
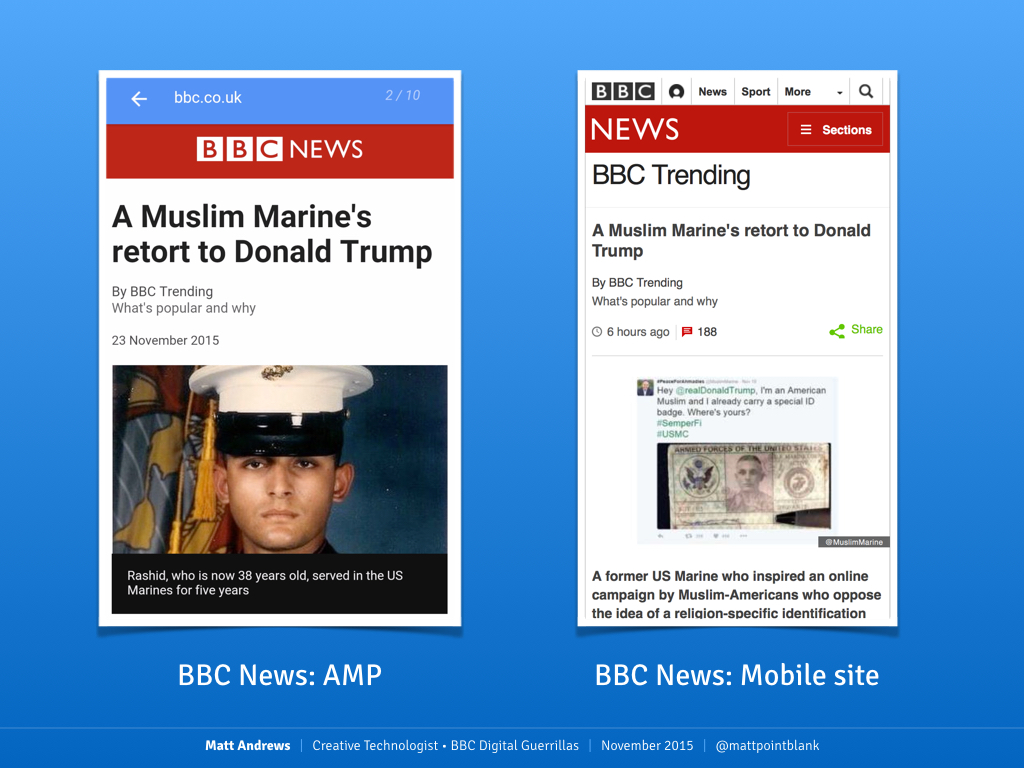
In case you didn't catch it from the clip, here's a side-by-side comparison of the BBC News site, showing the AMP version alongside the normal responsive web version. The differences aren't enormous but the AMP version is simplified and feature-limited.
The same BBC news story on AMP and BBC web, respectively.
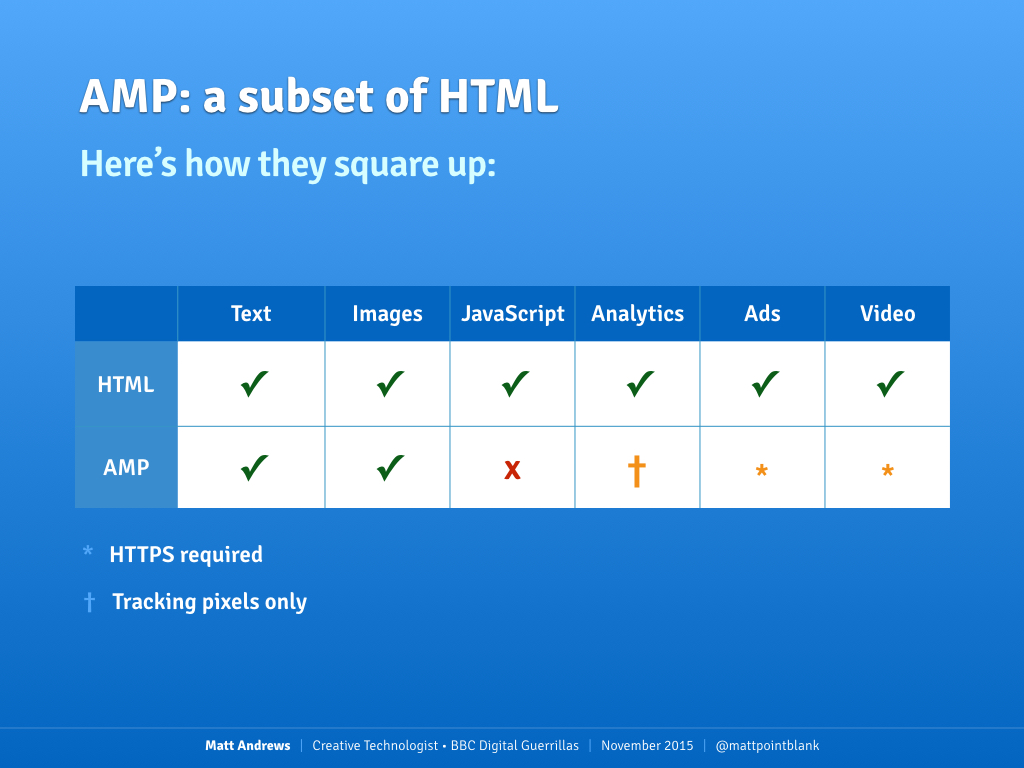
So how does AMP limit publishers? Here's a handy table to summarise:
A summary of HTML vs AMP
It's worth clarifying here that publishers can embed ads and video, they just have to be secure (eg. served via HTTPS). This probably isn't an issue for larger news sites which are in the process of moving to secure endpoints, but smaller publishers without strong technical expertise
may find this harder to implement.
Analytics is an interesting challenge: Google allow 90s-era tracking pixels which record basic page impressions, but little else. These days data gathering in the browser is a sophisticated operation and much of the data captured is client-specific: browser settings/feature support, screen dimensions and other things. Not all of this is available to a simple tracking pixel so data achieved from these trackers will be primitive compared to a full-fat website.
Despite these challenges, though, lots of major publishers are involved. The BBC, FT, Guardian and Daily Mail are among the large British publishers already implementing AMP versions of their content, and intriguingly, tech companies like LinkedIn and Twitter are joining too.
Google are trying to share the wealth here, at least figuratively – anyone can implement an AMP-friendly platform. If you wanted to build your own search engine which referred users to AMP-enhanced pages, all of the code is here for you to do
that.
2. Facebook Instant Articles
It's hard to talk about AMP without mentioning Facebook's own, earlier implementation of a similar concept. Launched earlier this year, Instant Articles offers users a similarly speedy version of the mobile which, which Facebook bemoan in their launch blogpost:
"Mobile web articles can take an average of eight seconds to load, by far one of the slowest parts of the Facebook app."
Here's a quick marketing video from Facebook showing how Instant Articles works in their iPhone app:
What I think is interesting here is that Facebook's concern for the slowness of the mobile web is centered around the experience of the users of their apps. They're effectively trying to speed up the entire mobile web in order to improve the rendering time of the slowest part of their native app. That's quite a dedication to performance.
Obviously Google, too, have something to gain from AMP making Google Search seem even more instantaneous. But there's more self-serving in Facebook's Instant Articles. Google's AMP is open source and implementable by anyone. Facebook's Instant Articles also claim to be made of open source standards, but we see little Facebook-specific snippets creep into the otherwise-kosher HTML5 they suggest:
<figuredata-feedback="fb:likes,fb:comments"><imgsrc="http://mydomain.com/path/to/img.jpg"class="no-margin"><figcaptionclass="op-left op-large"><h1>This is an image markup example</h1><cite>Photo by Jane Photographer</cite></figcaption><audioautoplay=""><sourcesrc="http://mydomain.com/path/to/audio.mp3"></audio></figure>
That data-feedback attribute? Non-standard, used to augment that particular piece of content when shown as an Instant Article on Facebook. I mean, fine – this is an easy way to let publishers add social features to their content. But it's not really the open web.
So how do these two efforts square up? Here's another table:
Features and ethos: Google AMP vs Facebook Instant Articles
Facebook lose points immediately for only being on iPhone. Instant Articles are currently only on iPhone, with Android support not yet implemented. No mention of the mobile web yet, where Google started their efforts. The difference is in their implementations: AMP is still HTML (albeit augmented by Google's JavaScript) and therefore renderable in a browser. Facebook are being characteristically vague about how they're serving Instant Articles, but it seems they're cached somehow and rendered out to the client according to customisation options chosen by the publisher.
That also covers the openness comparison: to publish your content as Instant Articles you need to be approved by Facebook, whereas you can start publishing AMP pages right now and Google will show them. Similarly, you control your rendering of AMP on your server, whereas with Instant Articles you're sending Facebook an RSS feed of your content which it ingests and spits out to (some of) its users.
There's no clear victor here just yet as it's too early for adoption number to be clear, but the fact we're even seeing this debate happen and these products emerge is fascinating in itself. My money's on Google because they're better at evangelising open standards like this (and have the heft to make them de-facto: see their work on the Blink rendering engine in Chrome). Facebook, on the other hand, have been here before: I myself worked on the Guardian's Facebook app which aimed to keep users inside the social network while reading Guardian content. That app was killed a year or so after we launched it due to declining interest from users (and Facebook). Have they learned the lessons and pivoted successfully? Time will tell.
3. Google Cardboard
This is another instance of Google having the scale (and budget) to alter the tech landscape in their chosen direction: here they're bringing cheap but impactful virtual reality to the masses, all for a tenner.
Yep: for about £9.99 you can snag one of the many (unofficial) Cardboard devices from Amazon, or if you're a super-nerd, construct your own. It's a basic cardboard frame which holds a smartphone and has a couple of lens (of different thicknesses/focal depths) for simple 3D viewing.
It's difficult in a text article to get across the experience of wearing the headset and experiencing a virtual reality, but Google's efforts to integrate 360° video into YouTube for desktop and mobile means you can get a basic idea even without Cardboard. The video below, by the Discovery channel, is filmed with 360° cameras and lets you pan around with the mouse (on desktop) or move your device through 3D space (on mobile) and see the entire field of view.
It's not just cutesy animal stuff though: the New York Times recently announced a partnership with Google where they'll be sending out a million Cardboard devices to NYT subscribers. Again, Google's massive scale makes this do-able, but it speaks to the Times' belief that virtual reality can make for incredible storytelling. Their app tells a story about refugees fleeing war: a strong, classic piece of journalism – and now being told through virtual reality headsets. If you work in publishing, or particularly in multimedia, you need to get on board with this right now – buy a cheap Cardboard headset and immerse yourself.
Hackers
For the second half of this article I'd like to talk about some web technologies that are exciting me from a more technical viewpoint. Hopefully they'll still be of interest to journalists as well as developers, particularly where they relate to the mechanics of web publishing.
1. Web Push Notifications
Google, once again, are pushing the web forward. Here they've begun to implement mobile push notifications – in the browser.
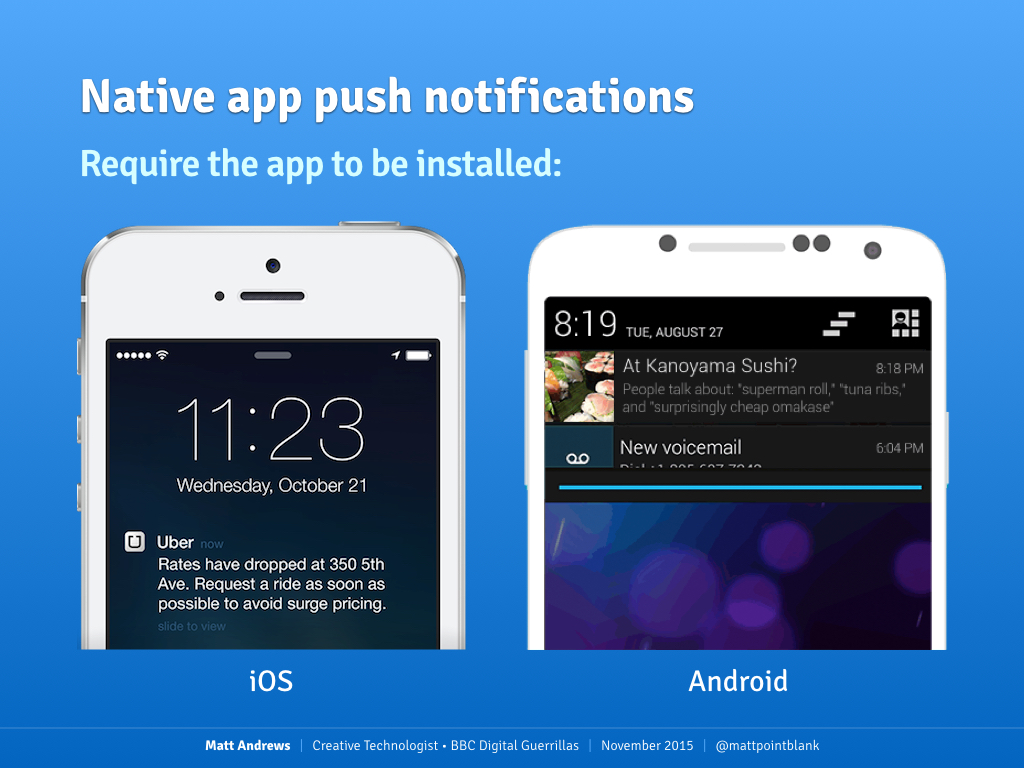
If you're not sure what I'm referring to, here's the kind you've probably seen before – iOS notifications on the left, Android on the right.
Examples of native app notifications on mobile
In order to send one of these to your user, there are a number of hoops you have to jump through. First is building a mobile app: not easy if you don't have the resources, and in the case of iOS, you even have to pay for the privilege. Next you have to actually get your user to install it – again, trickier if you're a small publisher whose users might not want to bother with a local/niche interest app. All of this is a barrier to entry, and if your user is on a platform you haven't developed for (maybe your budget only stretched to Android?) then forget it.
Web push notifications, on the other hand, are available to everyone – at least, in theory. If your browser supports them (which, at the time of writing, means Chrome 42 and Firefox 44 only) you can get an experience like this:
What does this mean for publishers? It means that with a fairly trivial amount of code, you can get permission from your user to notify them about things, and then you can alert them to breaking news or important information – even after they've closed the page and left your site. Now, with great power comes great responsibility, but crucially, this lowers the barrier to entry for publishers to tell their users things they care about.
2. WebSockets
Now, this isn't quite bleeding-edge tech anymore: most of us will have used them (probably unknowingly) in the past year or two, particularly on collaborative apps like Google Docs or liveblog content like BBC Sport.
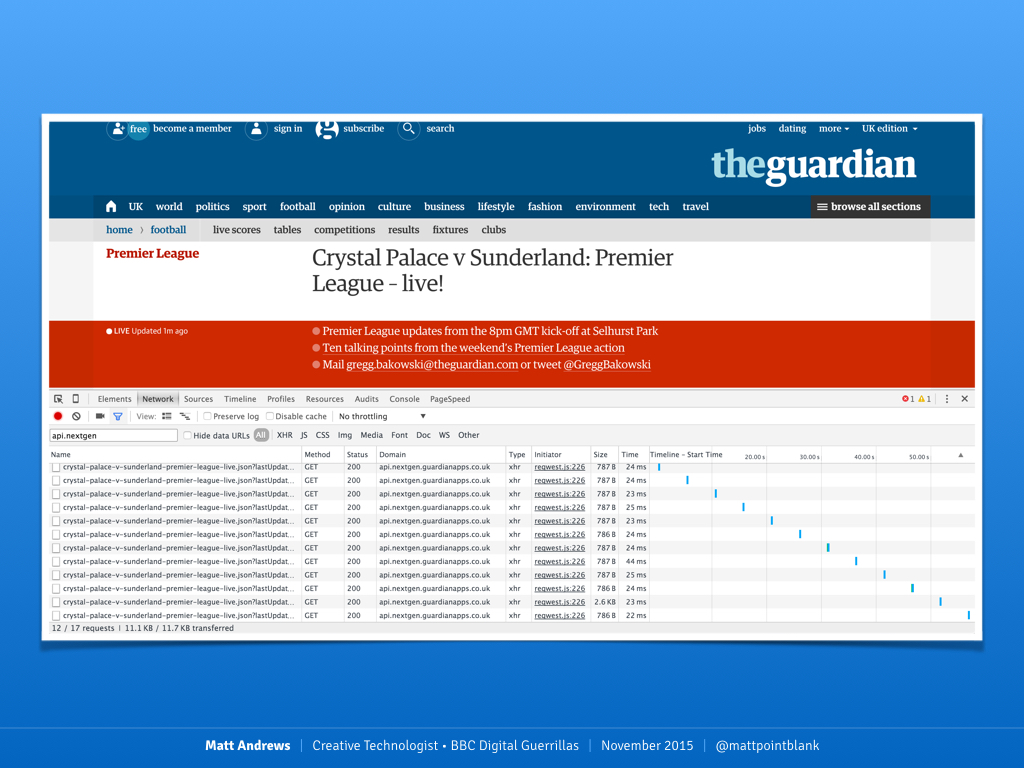
Here's an example. At the Guardian, they currently use classic AJAX requests to update their spot liveblogs. This screengrab shows a regular network request (every 15 seconds or so) pinging their Content API to see if anything has happened.
The Guardian website liveblog, with the developert tools open
This was the standard way to build this kind of page in the classic HTTP world: a client connects, requests a page, the page is served back and the connection closed. After that, the client makes repeated connections to request new data.
This technique is perhaps the technical equivalent of knocking on your friend's front door repeatedly every 15 seconds to see if they're home from work yet. There's a better way, though.
WebSockets open a permanent two-way connection between the client and server. Both sides of the connection can send messages on-demand, without a need to constantly poll for updates. This has the benefit of reducing the requests to your data layer: in the Guardian liveblog example, if a thousand users are on the page concurrently that's a thousand requests every 15 seconds for new data. By using WebSockets, only the server itself needs to make those requests, sending the results back to every connected client. 1 request every 15 seconds (or, one for every application server).
There are some downsides: WebSockets aren't supported everywhere (IE only got them in version 10), but the fantastic socket.io library makes them effectively work everywhere.
I built a silly demo to show how WebSockets can be used to make interactive pages too, where multiple clients can connect to the same socket instance and communicate with one another. Load this URL on a desktop browser, then connect to it from a mobile phone (use a QR code reader to read the code on the page and follow the URL). When you press the onscreen button on your mobile, the desktop instance should respond immediately. Google have already built some impressive multiplayer browser games using the very same technique.
3. ServiceWorker
This is a pretty new browser API that's still in development (currently only Chrome, Firefox and Opera support it). On the surface it seems fairly abstract: spawn a background worker to perform tasks by proxy of the host website. In detail, though, it effectively enables a host of offline web features.
The API allows you to specify files to save locally and then the ServiceWorker intercepts every subsequent request to the same site. This in effect means if the user goes offline and tries to request another page, you can detect this and serve them something offline.
The potential is massive though: it could cache the top five current news stories and offer them, or use the Guardian's "saved for later" feature to actually download those articles for offline reading. The potential for webapps is huge too: visit it once, then it's usable even when you have no network connection.
Conclusions
There are three things I hope you'll take away from this talk:
1. The web is too slow
(or so the big players reckon)
It's fascinating to see large companies like Google and Facebook try to take on the challenge of speeding up the mobile web. Both have form in this area and the reach and budget to make a serious go of it. The part I find most fascinating is the audacity of the idea, particularly Google's AMP proposition. They're effectively trying to wipe the client-side slate clean of everything the last decade has brought us, rather than wait for the W3C or other standards bodies to improve things.
It's an extreme approach and one that likely won't reach smaller, slower companies and their websites. But Google are pioneers when it comes to changing everyone's thinking on how things work (take GMail, Android and quite a few other products) and if anyone can pull it off, it's them.
On the other hand, is this just a power-play? Are Google and Facebook trying to effectively replace HTML with their own semi-proprietary solutions? Facebook in particular seem only interested in passing on the benefits to their users, rather than to the web at large.
2. Wearables and VR are coming
Or, to be honest, they're already here, and are only getting bigger. Oculus Rift, bought by Facebook, will be released early next year, and the impact it'll have on gaming will be enormous. Things like Google Cardboard aren't going to turn a nation into VR evangelists overnight but they're exciting, cheap and usable: within seconds of putting it on you get the idea immediately and understand how it works – and if you're canny, you start thinking of possibilities. If you're a storyteller, this is huge – imagine a drama you can interact with, rub shoulders with the cast, dig out hidden secrets and previously-unexplored territory. It's coming and it's awesome.
3. The web is starting to rival native apps
Google are super hot on this agenda and it shows. Their break from Apple in the form of dumping Webkit for Blink illustrates their commitment to bringing native app-like features to the open web. Whether you agree with their sometimes nonstandard methodologies or small army of earnest young men evangelising their tooling is your call, but it's hard to argue that they're not pushing things in the right direction. Apps are great but they shouldn't be the only way to do things: it's exciting to see what's coming down the track, and let's hope other browser manufacturers (hint hint, Apple) start to wake up to the possibilities.
I called this talk the blossoming of the web because it feels as though we're—slowly but surely—passing the awkward teenage years of the web and reaching a kind of maturity, even beauty, when it comes to the platform. Revolutions like web standards, jQuery and responsive web design have came taught us innovation and reinvention, and it genuinely feels like the APIs, the people and the creativity are coming together in harmony, or something approaching it. It's an exciting time to be making things for this blossoming web and I hope some of these things have excited you with their possibilities.
Many thanks to Agustin Palacio for organising the meetup and hosting the event.
]]>Where Is Everybody?2015-01-24T23:00:00+00:002015-01-24T23:00:00+00:00https://mattandrews.info/talks/2015/01/24/fermis-paradoxThe Democratic People’s Republic of Korea2014-11-05T23:00:00+00:002014-11-05T23:00:00+00:00https://mattandrews.info/talks/2014/11/05/north-korea-hermit-kingdomOnline “newspapers” and changing reading & writing habits2014-11-04T23:00:00+00:002014-11-04T23:00:00+00:00https://mattandrews.info/talks/2014/11/04/online-newspapers-and-changing-reading-habitsModeration in Moderation2014-10-25T23:00:00+00:002014-10-25T23:00:00+00:00https://mattandrews.info/talks/2014/10/25/moderation-in-moderationHow to brew beer2014-04-29T23:00:00+00:002014-04-29T23:00:00+00:00https://mattandrews.info/talks/2014/04/29/how-to-brew-beerSurviving the multi-device news challenge2014-01-22T23:00:00+00:002014-01-22T23:00:00+00:00https://mattandrews.info/talks/2014/01/22/surviving-the-multi-device-news-challengeIntroduction
I'd like to explain to begin with what I mean by "the multi-device news challenge". Here are a couple of big numbers:
322: the number of unique browser versions the Guardian gets traffic from in a month.
6236: the number of unique devices that traffic comes from per month.
82m: the number of unique readers sending us that traffic
(all stats for September 2013).
This is the multi-device challenge: anyone producing content for the web is facing it, and it's getting harder.
The last time I was here in Berlin it was 2007 and things were pretty different, particularly when it came to my taste in hairstyles. A few other things have changed since then too:
I now work at the Guardian newspaper in London. My job all day is basically this – playing around with HTML, CSS and JavaScript as a front-end developer. That code is a small part of this tool which I'm helping build: it's called Composer and it's used by Guardian journalists to create all sorts of content on our website. I'll be talking more about that later.
Composer, the Guardian's new content publishing app.
I'm here today with one aim: to convince you to make APIs for everything.
Wait, what's an API? Why does a newsroom need one?
Hopefully the hackers in the room will already be familiar with what an API is, but for those who aren't: what on earth is an API and why would a newspaper use one?
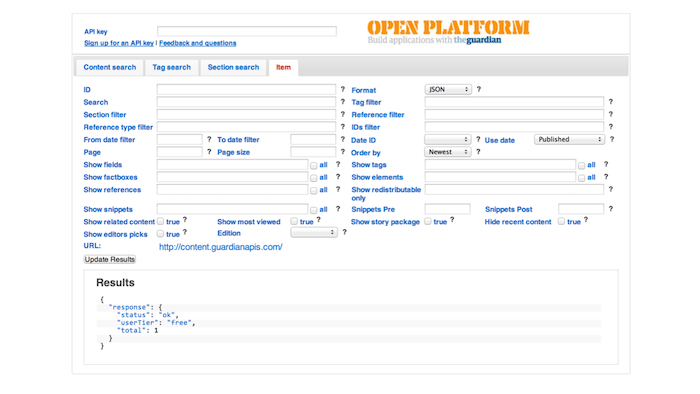
Well, to answer the first question: an API is an Application Programming Interface. In the Guardian's case, our main one looks like this:
Some JSON from the Guardian's Content API.
But that's boring. All we really need to know is that APIs are about communication. They're a way of building a layer that can mediate between different things and answer questions. For example:
show me the top five most-read articles
what are the current football scores?
add this reader's comment to the database
We use that data I showed a second ago to power all sorts of things, including the Guardian's new responsive redesign.
Three topics I'll cover:
Why should you have an API?
What will an API change about your process?
How can you create an API for your data?
I'll speak for around 25 minutes and then open things up for questions.
1. Why should I have an API?
The very first topic, then: why should you have an API?
It's a simple answer: because APIs make building new things trivial.
Here's a quick example of a bunch of different applications we've built using the Guardian's Content API:
the new responsive desktop website
... which also has a mobile view, too
the former Guardian Facebook app
our iPhone app
our Android app
our Kindle app
...plus a whole host of others. Not one of these applications required us to write any database code at all. All the data we wanted was already in our API, organised by section, tag, author and other filters. If you want to get the latest headlines for Sport which were marked by our editors as "lead content", it's a single API request.
Using APIs like this can be a huge benefit for scalability. Scaling software means making it capable of vast growth, allowing it to stand up when lots of traffic arrives. For a news website this is really important. Our API helps the Guardian do this and I'll quickly walk you through why that is:
Without an API, each platform you build on has to repeat code and connect to a database, re-implementing the same techniques for the same results each time. Each platform is separate and can't share cached data when the output belongs in different formats.
Introducing an API into this equation really simplifies things: now the back-end database could be swapped out and the client apps don't need to care about the data's source: they just go via the API. Scaling and caching can happen solely at the API layer, rather than on each separate platform. One API can support dozens of types of clients.
Thinking in multiple contexts
Another reason you should have an API: it forces you to think in multiple contexts.
What do I mean by that? Here's a quick example.
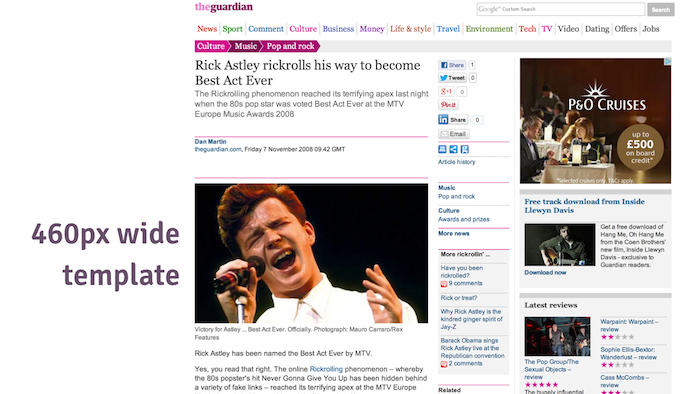
This is the Guardian's current desktop site. The article itself and the photo are designed to fit a 460 pixel wide template. This has been the case for at least five years or so.
The article design fixed to a 460px wide content template.
In the CMS we use to power this website, the tools themselves reinforce that concept:
The Guardian's legacy CMS, enforcing the 460px display limit.
Editors are so used to thinking of the website as being this 460 pixel column that everything we did was geared up to provide it for them.
The problem, of course, is that these days we see traffic from a huge array of different devices and screens:
This diagram shows common screen sizes for various devices. You can see that for quite a few of them, that 460 pixel template isn't suitable.
Lots of different device contexts.
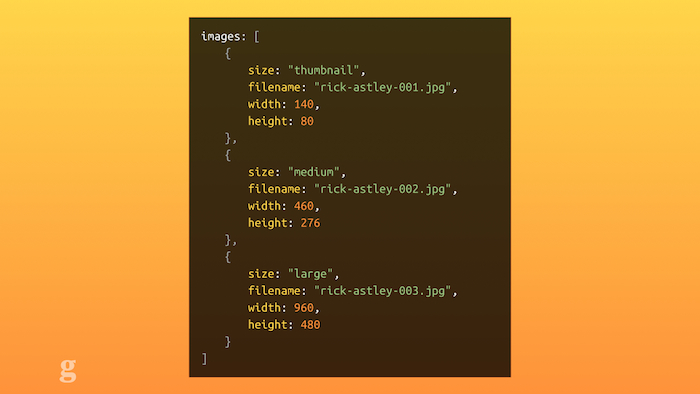
Once you switch from storing blobs of HTML for articles into a structured data format like our API, it forces you to think in these different contexts. An API is an abstracted way of representing your content: you have to break it down into logical elements: headlines, standfirsts, tags, etc. In our case, we break down images into different sizes like this:
JSON representing image sizes
It also helps that our API is used in that wide variety of contexts: every time we make a change to it, we have to think about what impact it might have. "How will this look in the API?" is a common question in our teams: we want to make sure we don't build assumptions into our products. Not every device will support Flash; not every screen is a 19" monitor.
External collaborators
Another benefit to having an API: other people can make things with your data.
The Guardian's Content API is open and public. Any of you sitting here now could make a request to it and get back our content: headline, images, article text and all. You might wonder why this is a good thing: surely this means other people can make their own bootleg versions of the Guardian?!
Well, yes: and that's fine. This is from the Google Play store: there are at least five Guardian-related Android apps – but we only made two of them. Those other three were made by random developers. They use our API to grab our content and present it to readers.
Different Android apps for the Guardian, official and otherwise.
Again, you may think this sounds terrible: surely the Guardian wants to control how its news is presented? Well, perhaps, but we know that people consume our content in different ways. If someone else wants to take the time to build another way of consuming our journalism, we still benefit: if someone is reading your content, they're reading your content. Doesn't matter if it's on the official app or a community version. As long as the content is clearly branded as the Guardian (which is one of our requirements for using the API), we still win.
2. How do APIs change your processes?
The second thing I'd like to talk about is how APIs can change your processes. What will be different once you start using one?
The primary difference is that you stop thinking of your website as a monolithic structure; a huge, interlinked bag of stuff, tightly coupled.
APIs help you "decouple" things: you can break different parts of your site up into logical blocks which are independent of one another. Let me give you an example:
The Guardian's legacy CMS
This is the Guardian's old CMS. It's a terrifying mess of arcane code and complexity. It does everything. Seriously. It can:
post new articles to the website
manage tags which we add to our content
upload images and search existing photo libraries
send emails to subscribers
create polls, competitions and quizzes
create a cached copy of the website in case it crashes
make new "microapps" which allow any new code to run on the site
create microsites which advertise commercial partners
... and a host of other improbable things. That CMS was also tied into our frontend code, eg. the templates and design which made up the desktop website.
What that meant was that when we wanted to update that frontend: e.g., change a font colour somewhere, we had to take down that entire CMS for 15 minutes while we deployed the changes.
A change that once upon a time required turning off the CMS for 15 minutes.
Can you imagine walking into the Guardian newsroom on a Monday morning and saying "sorry guys, could you just stop posting content for a bit while I change a font somewhere?". We did this every two weeks.
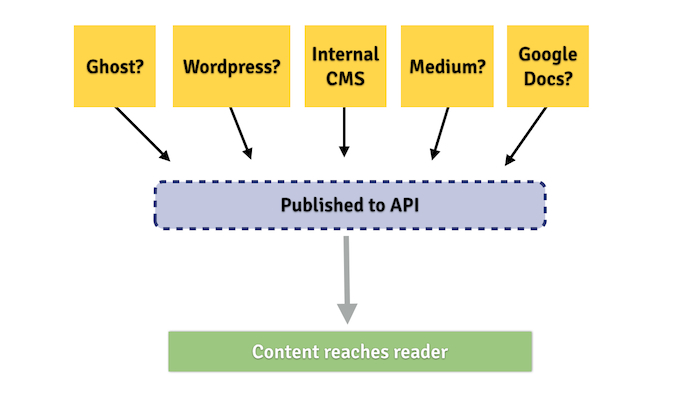
Our APIs mean we can abstract that process and break it apart. Composer, the new CMS we're building, pushes new content directly into our main Content API. It works independently of the front-end of the website, eg. the user-facing aspect of it.
This also means that publishing becomes multi-faceted: we can hook up any number of web publishing tools to our APIs as necessary. We don't have to view publishing as a one-to-one relationship. Building a single tool for journalists to use implies there's just one way to publish online. With an API, you can make it the "source of truth": as long as the data makes it to the API and is usable by its clients, the tools to input that data can be varied and different.
The publishing options open up when you have a good API.
Open linked data
It's also changed how we show related items and additional content. In the past we've tried things like embedding HTML widgets in content which do things like show videos or factboxes and other extra details. As with the template earlier, these bits of content often assume certain contexts that we just can't depend on anymore. By using linked data we can make this smarter.
Some of the ways the Guardian represents linked data.
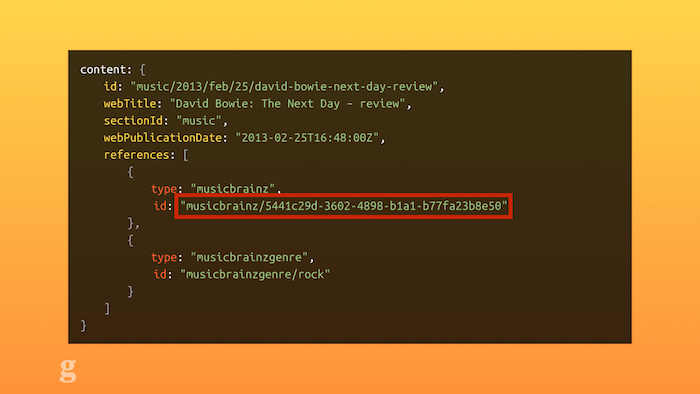
For example: a lot of our content uses tags to show its relationship: an article can be tagged as a review, as relating to David Bowie, as being a gallery, etc. But we also have a concept of "external tags": these are things outside the Guardian's taxonomy but useful still. For example, we can tag content with an ISBN, linking it to a published book. We can add tags for third party APIs, like the PA sport data, so we can show information about a live football match alongside the article. We can show information about albums by using MusicBrainz IDs to link our content. This kind of thing abstracts our content outwards: now other people can query Guardian content which has a MusicBrainz ID and do interesting things with it.
MusizBrainz IDs in the Guardian's API.
Once we get away from the idea of the web being a single thing, like a page of a newspaper we just arrange things on, we start to see why structured data with rich metadata around it is really important.
Take page layout: In the past, if you wanted an inline image, you'd have to insert one that was 200 pixels or less wide. This would be an implicit hint to our templates that it should sit alongside text. Again, this doesn't work anymore for all contexts. Instead, we're looking at how we can make these layout hints explicit: what if you could add metadata to embeddable objects to say "this thing should sit inline with this paragraph", which was then available in an API? Then you could be smarter and make different layout decisions based on the context you know up-front (the editorial story) and the context you know when rendering the page (the user's platform).
Hacking & experimenting
This is how simple it can be to get started with our API
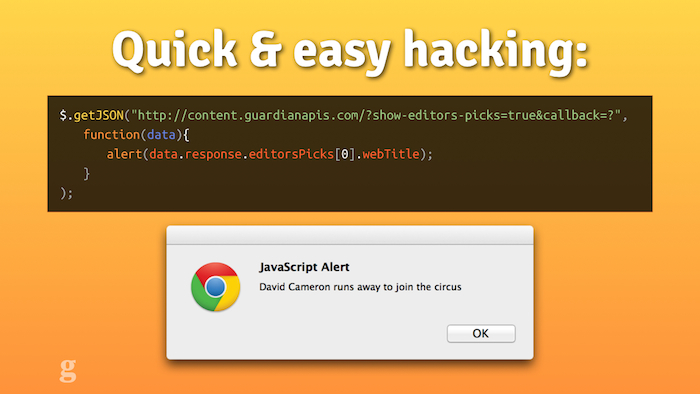
Another thing that changes once you have an API is creativity. I'm a front-end developer. The minute I have to start connecting to databases, writing SQL queries and caching, things are going to end badly. With a good API, though, I can quickly and simply grab what I need. This means that when we run departmental Hack Days at the Guardian, people can get up and running with real, live data in a matter of minutes.
Some Guardian developers making a Google Glass app with our API
At our hack day last week, some of our Android team built a prototype Google Glass app for the Guardian using our API. Could you imagine how much slower development would be on exciting new features if we had to write the same "boilerplate" code every time?
Writing your own API
The final thing I'd like to talk about, briefly, is how you go about writing your own API.
Now, I'm far from an expert on the topic: my only credentials for this are hacking together a data feed for SXSW 2011 when the official site didn't provide data for the gigs by various bands.
Before thinking about programming languages, hosting details or technical implementations, though, the first thing to work out is your content model.
Sit down in a room with journalists of all levels, if you're a developer, or grab a mix of your developers if you're a hack. Stay locked in that room with as much coffee as is necessary before you can work out what the constituent parts are of your content.
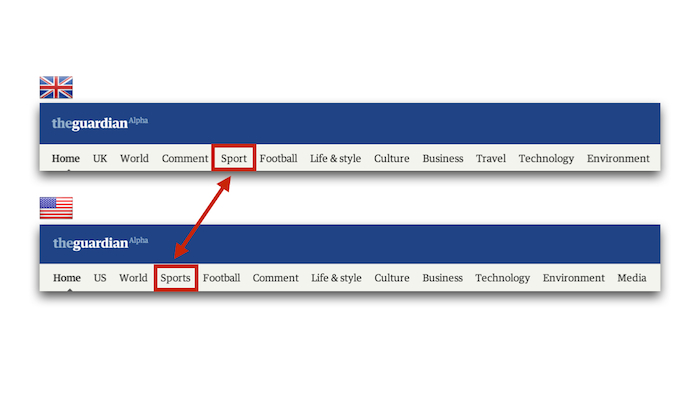
Think of it as a consumer: if you were a third party wanting to build things with your stuff, how would you expect it to work? If you're anything like us, you have a few weird quirks or inexplicable features which only your team worries about: for us it's things like remembering that in the Guardian American edition, we have to say "Sports", not "Sport". Can your API handle that kind of thing automatically? If your imaginary user shouldn't need to worry about it, you'll need to build it in.
Just one of the international considerations the Guardian has to make.
If you can, another tip is to build it with openness in mind. Your bosses, particularly the ones in charge of syndication, might not be too keen on programatically making all your journalism available for anyone to import. But then, your content's already on the web, right? If someone wants to steal it and they're committed enough, they can. We do things like embed ads into the article body text for external developers using our APIs. That way we still get some commercial benefit as well as the readership benefit when someone builds using our stuff.
Copying on the web has been around a lot longer than APIs...
Once you've come up with a model and figured out what to build it in, make it easy to query. The Guardian has a fairly unusable but popular console tool for exploring the API. Don't make it hard for developers to use your data or they'll give up and go somewhere else. The barrier to entry should be so embarrassingly low that everyone will want to start thinking up interesting things to do with your data rather than wondering what database library they'll use to connect to your content.
The Guardian's just-about-usable Content API explorer console.
Build it simple to start with. An insider tip: there's an internal Guardian API we use for analytics which requires an API key to use. One of the developers admitted to me privately that any string is a valid API key: all they use the key for is to track usage. If a certain key starts causing trouble they can just block it. This might not work for every use case, but when you're just beginning it can save you time writing complex rate limiting code when you might not need it for six months. What's the minimum work you can do to get something useful built?
Concluding thoughts
So, to conclude.
It's actually really straightforward: build an API. Now! If you work for a news organisation, hassle your bosses about letting you create one. Or just go ahead and make one anyway.
Maybe you already have an API – great? Is it open? If not, why not? There are lots of benefits to opening up your content to everyone: take advantage of them.
Why do you need an API? Once again:
building new things is much easier & quicker
they help you scale up
they get you thinking cross-platform by default
other people can do cool stuff with your data
Finally, one more big number to close with:
1. One person: that's you. Go and help your news organisation prepare for the future.
Many thanks to Annabel Church and the rest of the Hacks & Hackers Berlin team for organising the event, and to Nic Long at the Guardian for helping me research and fact-check this talk
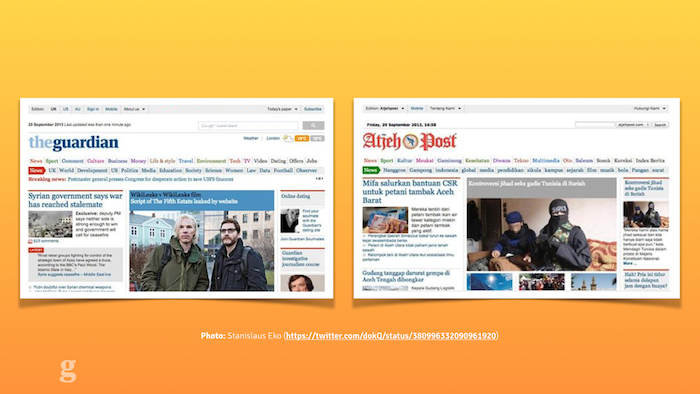
]]>Responsive design at the Guardian (Canvas Conf)2013-10-09T23:00:00+00:002013-10-09T23:00:00+00:00https://mattandrews.info/talks/2013/10/09/responsive-design-at-the-guardian-canvas-confA few weeks ago I was in central London near the river, waiting to cross the road. Just before the traffic lights changed, a huge yellow and blue truck-like vehicle came rolling past.
It was the London Duck Tour[1], famous for being the city's only "amazing amphibious adventure". You can see it here packed to the gills with tourists checking out the capital.
But the cool thing about the London Duck Tour is that it can go off-road:
That's right: if you've ever felt that the dirty, polluted water of the Thames feels too far away, you can take the plunge into the river thanks to the Duck Tour.
This got me thinking a little bit. That vehicle is actually prepared for the future. I don't mean it's got an electric motor or takes hybrid fuel. I mean it's built to handle pretty much anything:
If Kevin Costner's Waterworld ever becomes real, the London Duck Tour can just carry on as normal, ferrying tourists about to look at the sunken remains of Madam Tussaud's.
If 28 Days Later comes true, they're still covered: look at the front of that thing. No zombie's getting anywhere near it, leaving them free to look at all the swaying, dishevelled-looking people near Camden Market. Zombies, I mean.
Finally, if it's still around in 5.4 billion years when the sun expands and destroys all known lifeforms[2], it even has a way of putting out fires which might be blocking people's view of society crumbling into ash.
This is actually a pretty good metaphor for the web. For years we've been building very strictly-separated experiences, expecting our users to make the correct choice for us.
Even worse, sometimes there's no choice at all: quite a few websites still refuse to acknowledge that there's more than one way to access their content.
I'd like to talk to you today about how the Guardian is trying to build a platform a bit like the London Duck Tours: future-friendly, adaptive to change, and helping users see the best stuff no matter where they are.
Above all though, I want to convince you to make your website future-friendly[3].
I'm going to cover three aspects of our work: why we needed to do it, how we built it, and how we test it.
a) Why was it important for the Guardian to become future-friendly?
The answer is simple: the future is already here and our audience are already demanding it from us.
We're a global media organisation producing 350+ pieces of content per day to millions of users per day. You don't even want to imagine how long the list of devices is in our analytics software (6000+ devices across 300+ browsers in September 2013).
Various incarnations of the Guardian's mobile website.
Back in 2012 we were getting bogged down working with third parties on our lowest-common-denominator mobile website. We were working with a desktop website consisting of a hundred templates and over 600 components – on a fortnightly release schedule.
Making a website scalable doesn't just mean coping with huge traffic: it means coping with huge change. Our desktop site wasn't designed for that kind of adaptability, so we needed to throw it out and start again.
We had to build a platform capable of quick change.
How we became future-friendly
Okay: so how did the Guardian go about creating this new platform? What did we have to change?
Well, by definition: everything.
You could spend time trying to figure out everything you currently have on your site and working out what code is worth porting over and keeping, but the time spent doing this just wasn't worth the effort for us. A clean break was actually one of the most valuable aspects of the rebuild: it allowed us to ditch things that weren't working see who complained, rather than argue it out for every widget, button and promo component.
There were four main things we changed which I'd like to go over now and explain how they helped us succeed in planning for the future of the Guardian online.
1. Cutting the mustard.
The first step in rethinking the web for the future is accepting that making things look exactly the same across all browsers is an idea best left to the past.
The multi-device web means that there's no longer such thing as a single-experience website. This means we need a way to differentiate between experiences from a code perspective.
The BBC did some great work on this[4], devising a JavaScript test which would detect support for a number of core browser features and thus determine whether a given browser "cut the mustard" or not. Developer Tom Maslen put it best in a blogpost about their responsive work:
"[cutting the mustard is] an opportunity to wipe the client-side development slate clean."
We were inspired by this at the Guardian and followed a similar path to the BBC in deciding how to put our users into buckets. This is the code we use to decide which experience our users get:
If a browser has all three of these features, we consider it a "modern" browser and it gets the full-fat JavaScript application. If it doesn't (IE8, Firefox 3.5 and below), the JavaScript is never loaded and the user gets a page which is quick, lightweight and completely usable and accessible. They even get the ads.
Part of the goal here is to avoid punishing your users. We don't bother with jQuery or any other "do everything" library on the new Guardian site: most of the features we want like DOM querying and event binding exist natively now. For some features we use a bunch of microlibraries, but life is made much easier by not having to take broken browsers with us on the journey.
75% of our mobile traffic comes from either the iPhone or high-end Android devices running WebKit & Blink. These devices don't need polyfills: don't send any to them.
Ultimately: don't be afraid to build multiple experiences. Pixel perfection is an anti-pattern: reject it.
2. Integrated workflow.
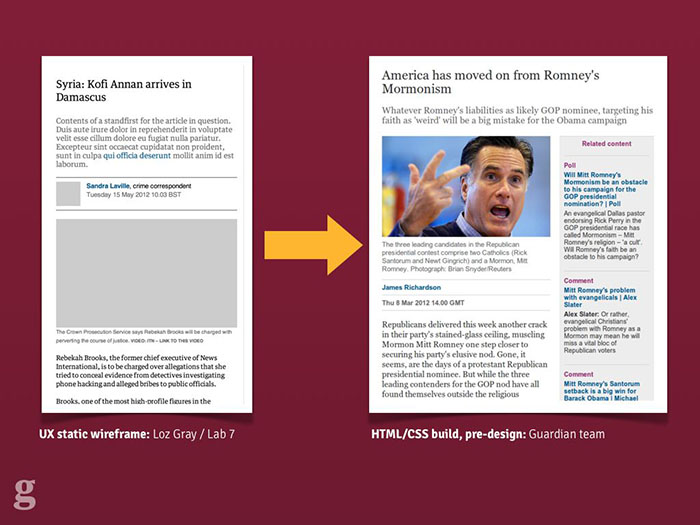
The second step in making the Guardian future-friendly was an integrated workflow. For us, this meant making UX and Design a part of the development team: not (just) producing "deliverables", but in the trenches with the software team and responding to new developments and tricky design challenges.
Some examples of the Guardian's UX process for the responsive mobile site.
Our process looked a bit like this: our UX Designer produced HTML wireframes illustrating the experience goals of the new site. These were deliberately colour-free and usually image-free too but served to get across the idea to multiple parts of the team without having to be too fleshed-out. We were lucky enough to have a UX specialist with a strong front-end web development background too[5]: this meant his UX mockups were fully responsive. When it came to demoing ideas to stakeholders, it meant that even from the wireframe stage, they were getting the idea that this was a website with more than one visual experience.
From there it was over to our designers to interpret the wireframes and begin marking out the visual language of the Guardian. We chose not to stick with the "classic" Guardian style, which also coincided with the Guardian hiring its first-ever Creative Director for our digital products. The new site therefore got a strong and bold new look which was dramatically different from what came before.
An image of the new, experimental desktop design for the responsive site.
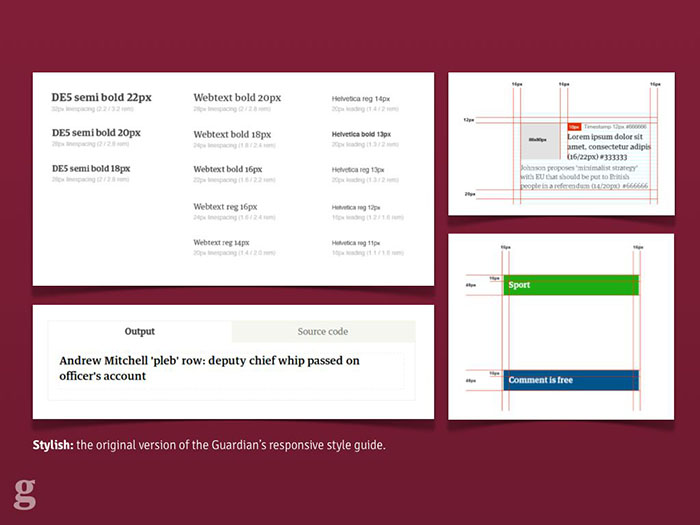
After the first few exploratory designs, we began to integrate the design team into the software team so they could see the results of their work and so developers could feed back and ask questions as they worked, not afterwards. We built a live style guide using the repeated components across the site, and agreed on standardised typography classes with shared names between design and development. This kind of approach made refactoring things much easier when designs were updated.
The styleguide built inside the responsive app itself, used to share and communicate design ideas.
For years at the Guardian we've worked in cross-functional teams in terms of development: integrated front-end, back-end and QA. With this project though we were able to integrate UX and design into that team and the benefits have been huge. I'd argue that it's impossible to deliver a well-built responsive site without a unified team, even if it involves bringing in agencies or contractors into your office to work.
3. Features over devices.
Too many people mistake responsive design for "building three websites: mobile, tablet and desktop". Here's how they should be thinking about it
"Cutting the mustard" leaves us with two types of browser: "modern" and, er, "ancient". This doesn't mean they're all equal within these buckets, though.
At this point some people start to panic and just design their site around specific device models like the iPhone 4 or the new iPad. Thinking like this doesn't scale and the solution is actually easier: if we use progressive enhancement as our guide, a lot of things come for free.
Progressive enhancement begins around one thing. It's not "make it work in IE6 first", it's not "build it without JavaScript". It's simple: build your website content first.
At the Guardian we looked at each page and worked out what its "core content" was. This wasn't hard: for an article page, the core content was the headline, the main photo and the article body. Everything else was considered non-core and could be dropped if necessary. Once we had this starting point, we could begin writing code.
We now knew that whatever happened, whether the user didn't support JavaScript, CSS, or was accessing the site on a GameBoy Advance, they had to be able to see that core content.
This opened things up: again avoiding the tyranny of "pixel-perfect" design, it was okay to say that users who failed our "modern browser" test wouldn't get our "related content" widget, which loads via AJAX. People who didn't support WOFF or TTF wouldn't get our web fonts.
One common error with building sites for the mobile web is faulty assumptions like this one: device size is equivalent to network speed.
We've all been here: too lazy to grab a laptop or desktop instead. Source.
We know this isn't true: how many of us browse the web on a smartphone while sitting at home connected to wifi? Likewise, who's experienced the pain of connecting their high-end laptop to the extortionate "wifi" you pay for on trains? The size of the screen isn't a reliable indicator of the connection speed.
I'd like to show a quick video I made showing page load experiences for different British news websites: the Guardian, the BBC, the Telegraph and the Daily Mail. I recorded these while simulating an Edge mobile connection – eg. slower than 3G. This might not be a typical user's experience, but for the poor person stuck on a stopped train or in a field in Glastonbury, this may well be their experience of the mobile web. Let's take a look.
Warning: some viewers may find the following clip distressing.
Warning: I make no claims for the scientific accuracy of this test, but it gives an approximate idea of the times involved.
Now, perhaps I should point out that for whatever reason – in 2013 – the Daily Mail doesn't have a mobile website, let alone a responsive one. I assume they want users to download their apps rather than use the mobile web. But if you do try to load their whopping 8mb homepage over Edge, you'll be waiting for...
... 30 minutes. Or at least, that was when I got bored waiting for it to finish and stopped recording.
This means it's our responsibility to not make assumptions: just because someone's loading our desktop website, doesn't mean they're on a super-fast network. We need a way of making decisions based on connection speed.
Luckily for us, there's already a specification for helping figure this out. We use the window.performance object[6] at the Guardian to calculate real timings for the page serve speed, and make decisions about whether to upgrade low-res images or web fonts based on this.
This doesn't work in all browsers yet (notably Safari), but that's fine: only browsers which cut the mustard will get this code. Older browsers will be given the low-resolution experience, or we'll assume they're on a slow connection initially.
Google's touchscreen laptop, the Chromebook Pixel. Source.
Another mistake people make is assuming that a mobile device means a touchscreen. Our image galleries load in keyboard navigation for non-touch devices, and swipe navigation for anything with a touchscreen. We made a mistake here though: we assumed those two features were mutually exclusive. Then Google came along with the Chromebook Pixel and it turns out a device can now have a keyboard and a touchscreen. Good feature detection can mean you're future proof against these sorts of devices.
Some people think that the content itself should differ based on device. While I think this makes sense for certain cases, where you might not want to display a large component by default on a smaller screen, in general I think this is bad content strategy. Here's an example.
A Guardian editor (who will go unnamed) once said something along these lines in a planning meeting for the responsive site:
"If a user is on a mobile device, we should show news about the latest iPhone more prominently"
The reasoning there was that we know the user is on an iPhone, so we infer that they'd be interested to know when a new one is coming out.
This sounds reasonable enough until we stop to think about it a little. If I'm sat at home listening to the Beatles on vinyl, I don't put on my iPod and listen to One Direction when I go outside. Tastes and interests don't magically change when people switch device. If I care about the iPhone, I care about the iPhone. Show me news about it wherever I'm browsing from.
Sgt. Peppers is great, so why would I go changing? Source.
Of course tailoring content to users more likely to be interested in it is a really smart thing. The key is to personalise it by interest, not by hardware.
3. Swimlaning.
When I first joined the Guardian, we released an update to "R2" – the monolithic codebase which powered everything from the frontend of the site through the editorial CMS backend – once a fortnight. This was a scary process which involved key team members coming into work early on the morning that we did it in order to "supervise" the release. It meant that we had to take everything down for 15 minutes while the release happened: you can imagine how excited Editorial were when we had to remove their access to the CMS for a quarter of an hour so we could update a line of CSS.
Eventually we hacked on ways to update the code independently of an R2 release cycle, but something was broken and we needed to fix it with the new responsive site. The solution was swimlaning.
Swimlaning basically involves splitting out all of your services so they're independent and unable to conflict with one another. The Guardian desktop site was once brought down by a failure on our commenting platform[7]: the pages would wait for a blocking response from that server. If it slowed down, our content servers slowed down too. Swimlaning removes that problem.
The responsive site has a separate set of Amazon AWS servers for each "application" within it: e.g. the "articles" app, the "gallery" app, the "front pages" app and so on. Each of these can be released independently without touching the others. If one goes down, the others remain unaffected. We can give more heavily-trafficked apps more server resources and balance our spending with Amazon. Best of all, it makes deploying changes absolutely trivial, with a neat command line interface for pushing things out quickly and without fear.
Swimlaning doesn't just relate to architecture: we try to apply it to the code itself, too. Our site loads adverts and promotional items whose content we usually can't control. This means we have to sandbox as much of our code as we can.
A large part of this is following the AMD specification[8] for our JavaScript so it avoids the global namespace and uses pub/sub methods to communicate between modules. This protects us from adverts which might load their own libraries in and overwrite ours. We also try to do this with CSS: we use Sass, following Jonathan Snook's SMACSS framework[9]. Although CSS can't be sandboxed in the same way JavaScript is (until Web Components are done), using less-specific selectors which are carefully namespaced means there's less chance of third party code changing our body text to Comic Sans.
Speaking of advertising: that's one area we're struggling to properly swimlane. Most of the ads load code like this:
We've tried dumping this kind of thing inside <iframe>s so they at least don't block rendering for our content, but some ads need to break out and expand and this is tricky to handle from a frame.
The advertising industry hasn't caught up to HTML5 yet, let alone the responsive web. There are some startups doing interesting things around responsive ads but ultimately it's going to need the whole ad industry to jump ship or evolve before they'll succeed. It's a tough challenge.
The other main benefit of swimlaning is that it means there's no such thing as "big bang" releases. These are the worst thing for products: there's the expectation and "reveal" moment which inevitably results in surprise and shock from people who haven't seen it before. Our release process means we were able to publicly share what we were doing almost as soon as we had something that worked. By working in the open like this it removes the fear of the "big reveal" moment and means we got feedback about things that weren't working much earlier in the process. All of our code is public on GitHub for the same reasons.[10]
The upshot of working like this is that on launch day, we knew exactly what was going to happen – there were no nasty surprises as we'd already been running beta users through the stack for months and had been deploying to dozens of times a day. We knew it could take the load and we knew a decent chunk of the audience had already seen the new site and given feedback so it wouldn't be a shock. The confidence this gave the team has been hugely beneficial.
c) Testing for future-friendly status
The short answer is: accept that it's almost impossible to test things across all devices, browsers and contexts. Once you get over that, you're halfway there.
For us, we only had a single dedicated QA tester on the project, which might sound hugely minimal. This meant that our automated tests had to be pretty bulletproof to avoid dragging out releases with a full suite of human-powered regression testing.
We also knew from our analytics which devices were most popular among users – 50% alone were using iPhones. This made it easier to prioritise the devices we tested with. We have a cupboard full of various phones, tablets and laptops which we test on, and we also use some cloud-based tools to simulate rendering on other browsers and contexts. We relied on RUM – Real User Monitoring – to tell us the rest.
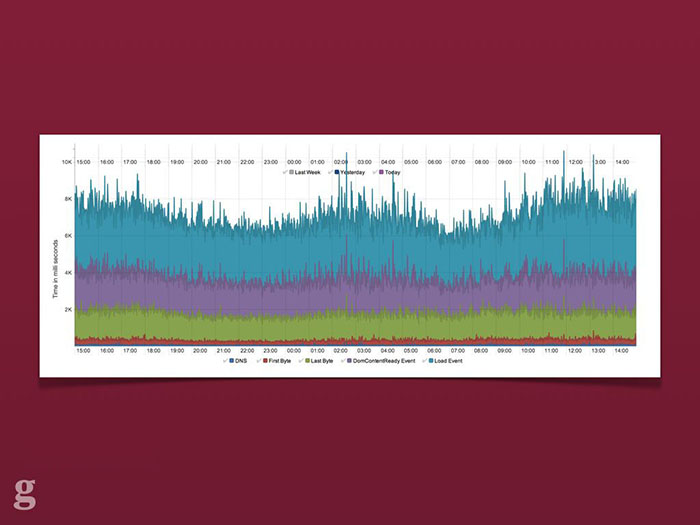
A screengrab from Ophan, the Guardian's internal analytics tool. It shows various page rendering metrics over a 24 hour period for the responsive Guardian site.
This involved setting up dashboards which logged all sorts of client information: time to first byte, JavaScript error count, page rendering time and so on. We look for spikes in these graphs – sent from real users – after a release. If something abnormal appears we can look into it and quickly push out a release. We learned that being able to quickly and simply diagnose a fix is more efficient and speeds development than trying to anticipate everything that might possibly go wrong in advance.[11]
As an aside: the more we make use of progressive enhancement, the less likely it is that we'll be woken up at 3am with a critical bug. Even if our JavaScript fails or our commenting server falls down, readers will still be able to read the news.
Conclusion
So, to conclude. What I want is for you to reconsider your current web offering. You might have already "gone responsive", but is this enough? Responsive design is just one aspect of being future-friendly. Are you ready for what happens when "responsive" itself becomes outdated and in need of replacing?
The benefits to the Guardian of rebuilding our web platform to be "next generation" are clear:
Our core content is optimised to be always-available, very quickly, to any class of device and browsing context
Our infrastructure means we can release things quickly and trivially without downtime or rollbacks
We don't spend half our lives testing everything because our monitoring and progressive enhancement give us confidence
When the next big thing rolls around, we can quickly update the relevant parts of the application without having to commit to a full-scale rebuild (like we've had to do now!)
At the start of this talk I mentioned the London Duck Tour and how it's a great metaphor for a future-friendly web. What I didn't show you (because it happened a week before this conference) was that recently, a Duck Tour boat accidentally set on fire during a tour and tourists were forced to abandon ship in the Thames right next to the Houses of Parliament.[12]
The London Duck Tour, sadly on fire. Nobody was harmed, luckily. Source.
When I first heard this news I was mildly devastated that my intro analogy was going to become a laughing stock. The Duck Tour hadn't been able to adapt for the future where it caught fire and sank.
The more I thought about it, though, the more it made sense. Responsive Design came along a couple of years ago to wake us up to the fact that screen size and device form factor were important and we couldn't keep building experiences separately. Here we are in 2013, though, and the landscape is even more complex and divided. Responsive, as a vehicle for bringing us to this point, has been incredible: it's changed how we work and how we build things. But it's only a part of the journey.
The fire gets put out as tourists are whisked to safety. Source.
Building things for the web means we shouldn't be bound to one "holy grail" technique or tool. Most of us have been doing this for long enough to see the cool new flavour of the month become old and unfit for purpose: look at jQuery, for example. Once it was an integral part of any website, no matter how trivial. These days, though, more and more larger sites are realising they can do without it. And that's fine. That's what the jQuery authors want: to get to a web where the browser APIs are standardised and equal, to reach a point where we don't need to polyfill broken browsers.
Roads? Where we're going, we won't need roads. Source.
If I say "responsive design is dead", it's because the ideas Ethan came up with in 2010[13] have been so widely recognised as smart and crucial and it's been so widely adopted that it's done its job: it's moved the web forward where we're all thinking about multi-device experiences. It's our job now to keep moving with that wave; stay on top of it and not let our guard down again like the poor chaps from the Duck Tour. We need to be ready for anything and build for a web platform which constantly evolves and transforms. Being future-friendly won't get us all of the way there, but it means that when the unexpected becomes the norm, it's not going to take us by surprise.
























{kind=link}